„So wie die alte Software.“ Fünf Worte, die nach klaren Anforderungen klingen. In der Praxis sind sie der Beginn eines Projekts, das fast immer teurer und langwieriger wird als geplant. Wer Legacy Software ablösen will, stößt nach dutzenden solcher Projekte auf dieselbe Erkenntnis: Diese fünf Worte sind keine Anforderungsspezifikation. Sie sind eine Falle.
Die unsichtbare Komplexität
Bestandssoftware, die über Jahre oder Jahrzehnte gewachsen ist, enthält weit mehr Funktionalität, als auf den ersten Blick sichtbar ist. Das liegt in der Natur gewachsener Systeme.
Da ist der Jahresreport, an den gerade niemand denkt, weil er nur einmal im Jahr läuft. Die 47 Sonderfälle, die über die Jahre eingebaut wurden, ohne dass sie je dokumentiert wurden. Die Schnittstelle zu einem Drittsystem, die ein Kollege vor fünf Jahren eingerichtet hat und die seitdem „einfach läuft“. Die Berechtigungslogik, die so komplex ist, dass niemand mehr erklären kann, warum bestimmte Nutzergruppen bestimmte Funktionen sehen und andere nicht.
All das ist funktionale Komplexität, die im Alltagsbetrieb unsichtbar bleibt. Sie taucht nicht in der Benutzeroberfläche auf, nicht in der Schulungsunterlage und meistens nicht in der Dokumentation. Sie wird erst sichtbar, wenn jemand versucht, das System nachzubauen, und feststellt, dass die sichtbaren 70% der Funktionalität vielleicht 40% des tatsächlichen Aufwands ausmachen.
Für die Projektplanung bedeutet das: Eine Aufwandsschätzung, die auf dem basiert, was Nutzer sehen und beschreiben können, unterschätzt den tatsächlichen Umfang systematisch. Die unsichtbare Komplexität taucht erst während der Umsetzung auf, in Form von Rückfragen, Nachspezifikationen und Korrekturen.
Die falsche Frage: „Genau das Gleiche nochmal“
Die zweite Falle liegt in der Annahme, dass die alte Software den heutigen Bedarf korrekt abbildet. In den meisten Fällen tut sie das nicht.
Hat sich die Welt in den letzten 10 Jahren nicht verändert? Neue Prozesse, neue gesetzliche Vorgaben, neue Anforderungen aus dem Markt? Funktionen, die vor 10 Jahren wichtig waren, werden heute möglicherweise gar nicht mehr genutzt. Und Funktionen, die heute gebraucht werden, existieren in der alten Software nicht, weil sie nie eingeplant waren.
„So wie bisher“ ist oft nicht die durchdachte Anforderung, als die sie erscheint. Es ist die bequemste Antwort, weil sie niemandem abverlangt, wirklich nachzudenken. Es ist einfacher zu sagen „mach es wie vorher“ als sich hinzusetzen und zu analysieren, was heute tatsächlich gebraucht wird.
Das Ergebnis: Eine neue Software, die alte Probleme originalgetreu reproduziert. Inklusive der Workarounds, die Nutzer über die Jahre entwickelt haben, weil die Software ihren eigentlichen Bedarf nicht abgedeckt hat.
Was stattdessen funktioniert
Ablöseprojekte, die gut laufen, behandeln die alte Software als Informationsquelle, nicht als Blaupause. Der Unterschied liegt im Vorgehen.
Anforderungen neu definieren, nicht kopieren: Statt die alte Software Feature für Feature nachzubauen, wird gefragt: Was brauchen die Nutzer heute? Welche Geschäftsprozesse soll die Software unterstützen? Welche Probleme soll sie lösen? Die alte Software liefert dabei wertvolle Hinweise, welche Funktionen tatsächlich genutzt werden. Aber sie definiert nicht, was die neue Software können muss.
Funktionsnutzung analysieren: Welche Funktionen werden täglich genutzt? Welche monatlich? Welche seit drei Jahren nicht mehr? Diese Analyse liefert ein realistisches Bild des tatsächlichen Bedarfs. In fast jedem Ablöseprojekt stellt sich heraus, dass 30 bis 40% der Funktionen der alten Software nicht mehr oder kaum noch genutzt werden. Diese Funktionen nicht nachzubauen, spart erheblichen Aufwand, ohne dass jemand etwas vermisst.
Unsichtbare Komplexität aktiv suchen: Vor dem Projektstart gezielt nach den Dingen fragen, die nicht offensichtlich sind: Welche Reports gibt es? Welche Schnittstellen? Welche Sonderfälle? Welche zeitgesteuerten Prozesse? Welche Berechtigungsregeln? Diese Erhebung kostet Zeit am Anfang, spart aber ein Vielfaches an Überraschungen während der Umsetzung.
Die Ablösung als Chance nutzen: Ein Ablöseprojekt ist der ideale Zeitpunkt, um Prozesse zu hinterfragen. Nicht nur die Software wechselt, auch die Abläufe können verbessert werden. Unternehmen, die diese Chance nutzen, bekommen am Ende nicht nur eine neue Software, sondern auch bessere Prozesse.
Warum „schnell ablösen“ selten funktioniert
In vielen Ablöseprojekten herrscht Zeitdruck. Die alte Software wird abgekündigt, der Support läuft aus, die Technologie ist veraltet. Die Versuchung ist groß, die Analysephase abzukürzen: „Wir wissen doch, was die Software macht. Einfach nachbauen.“
Diese Abkürzung rächt sich fast immer. Die ersten Monate laufen scheinbar gut. Dann tauchen die Sonderfälle auf, die niemand dokumentiert hatte. Die Buchhaltung meldet sich, weil der Jahresabschluss-Report fehlt. Die Fachabteilung stellt fest, dass eine Funktion, die als unwichtig eingestuft wurde, doch geschäftskritisch ist.
Jede dieser Nachforderungen kostet mehr, als eine gründliche Analyse am Anfang gekostet hätte. Nicht weil die Analyse teuer ist, sondern weil Änderungen während der Umsetzung um ein Vielfaches aufwändiger sind als Klärungen vor dem Start.
Realistische Erwartungen setzen
Ein Ablöseprojekt ist kein einfacher Technologietausch. Es ist ein Neubauprojekt mit dem zusätzlichen Anspruch, die Erfahrungen aus dem Altsystem zu berücksichtigen. Das macht es nicht einfacher als ein Neuprojekt, sondern in manchen Aspekten komplexer, weil die Erwartungshaltung durch die bestehende Software geprägt ist.
Realistische Erwartungen sehen so aus. Die neue Software wird in der ersten Version nicht alles können, was die alte konnte. Das ist kein Scheitern, das ist der normale Verlauf. Die alte Software hatte Jahre, um zu dem zu werden, was sie ist. Die neue Software deckt in der ersten Version die 80 Prozent ab, die 95 Prozent des Geschäftswerts ausmachen. Die restlichen Funktionen folgen iterativ, priorisiert nach tatsächlichem Bedarf.
Fazit
„So wie die alte Software“ klingt nach einer einfachen Anforderung. In der Praxis unterschätzt sie die unsichtbare Komplexität gewachsener Systeme und verhindert, dass die Ablösung als Chance für Verbesserungen genutzt wird. Ablöseprojekte gelingen, wenn Anforderungen neu gedacht werden, statt alte Funktionslisten zu kopieren. Die alte Software ist eine wertvolle Informationsquelle. Aber sie ist keine Blaupause für die Zukunft.
In jeder Debatte über technische Schulden tauchen dieselben Fragen auf: Wie entstehen sie? Wie bauen wir sie ab? Welche Strategien helfen? Diese Diskussionen bleiben aber fast immer innerhalb der Technik-Bubble. Was fehlt, ist die Perspektive des Projektmanagements und des Controllings. Die Fragen, die eigentlich gestellt werden müssten: Warum lässt ein Projektbudget technische Schulden überhaupt zu? Warum priorisiert das Management neue Features statt Stabilität? Warum wird der Abbau immer wieder verschoben?
Warum technische Schulden unsichtbar bleiben
Die Antwort liegt in einer grundlegenden Eigenschaft technischer Schulden: Sie sind nicht sichtbar. Nicht für das Management, nicht für das Controlling, oft nicht einmal für den Kunden.
Menschen reagieren auf das, was sie sehen und anfassen können. Ein überquellender Briefkasten wird geleert, ein tropfender Wasserhahn repariert, ein Müllsack im Flur weggeräumt. Das passiert automatisch, weil das Problem offensichtlich ist und das Wegschauen Unbehagen verursacht.
Veraltete Abhängigkeiten, fehlende Tests oder eine gewachsene Architektur erzeugen kein solches Unbehagen. Sie sind für niemanden außerhalb der Entwicklung sichtbar. Der Code funktioniert weiterhin. Die Anwendung läuft. Der Kunde merkt nichts. Warum also Geld ausgeben, um etwas zu reparieren, das von außen betrachtet nicht kaputt ist?
Die Analogie zu Finanzschulden
Bei Finanzschulden funktioniert der Tilgungsmechanismus, weil er eingebaut ist: Du nimmst einen Kredit auf, zahlst Zinsen, und der Druck zur Rückzahlung ist real und messbar. Bei technischen Schulden fehlt dieser Mechanismus vollständig.
Die Schulden wachsen still. Jeden Monat ein wenig mehr. Und irgendwann werden die Auswirkungen spürbar, aber auf eine Art, die sich schwer einem einzelnen Ursache-Wirkungs-Zusammenhang zuordnen lässt.
Features dauern doppelt so lange wie früher. Bugs treten häufiger auf und sind schwerer zu lokalisieren. Neue Teammitglieder brauchen Wochen statt Tage für die Einarbeitung. Release-Zyklen werden länger, weil jede Änderung unerwartete Seiteneffekte produziert. Das Team wird vorsichtiger und frustrierter.
Jedes einzelne dieser Symptome hat auch andere mögliche Erklärungen. Deshalb ist es so schwer, den kausalen Zusammenhang zwischen technischen Schulden und den beobachteten Problemen herzustellen. Und deshalb wird die Ursache so selten adressiert.
Niemand kann genau vorhersagen, wann der Kipppunkt erreicht ist. Aber wenn er erreicht ist, kostet die Sanierung ein Vielfaches dessen, was die laufende Pflege gekostet hätte. In manchen Fällen wird die Sanierung wirtschaftlich unmöglich, und das einzige verbleibende Mittel ist ein Neubau, mit all den Risiken und Kosten, die das mit sich bringt.
Warum der Abbau immer wieder verschoben wird
Das Muster ist in fast jedem Projekt gleich: Das Team weiß, dass technische Schulden existieren. Die Schulden stehen möglicherweise sogar im Backlog. Aber wenn es um die Priorisierung geht, gewinnen neue Features. Immer.
Das hat rationale Gründe. Ein neues Feature hat einen sichtbaren Geschäftswert: Der Kunde hat es angefragt, der Vertrieb braucht es, das Management erwartet es. Die Reduktion technischer Schulden hat keinen sichtbaren Geschäftswert, zumindest nicht kurzfristig. Sie macht vorhandene Dinge besser, aber sie erzeugt kein neues Feature, das man vorzeigen kann.
Dazu kommt: Wer vorschlägt, Sprint-Kapazität für den Abbau technischer Schulden zu reservieren, muss erklären, warum. Und diese Erklärung erfordert technisches Verständnis auf Seiten des Empfängers. „Die Architektur ist gewachsen und muss refactored werden“ ist für das Controlling keine handlungsleitende Information. „Wir verlieren jeden Monat 20 Stunden Entwicklerzeit durch Workarounds, die nach einem Refactoring entfallen würden“ dagegen schon.
Technische Schulden sichtbar machen
Der Weg, technische Schulden aus der Technik-Bubble zu holen, führt über die Sprache des Managements.
In Euro rechnen: Nicht in Story-Points, nicht in „technischem Risiko“, sondern in tatsächlichen Kosten. Wie viele Stunden pro Monat gehen für die Arbeit mit veraltetem Code drauf? Wie oft verzögern sich Features wegen technischer Altlasten? Was kostet ein Ausfall, wenn die fragile Stelle bricht? Diese Zahlen sind schätzbar, auch wenn sie nicht exakt sind. Eine grobe Schätzung in Euro ist für das Management handlungsleitender als eine präzise Beschreibung des technischen Problems.
Regelmäßig berichten: Technische Schulden gehören in den Projektbericht, nicht nur in die Sprint-Retrospektive. Wenn das Controlling sieht, dass jeden Monat 20 Stunden in Workarounds fließen, wird der Business Case für die Sanierung nachvollziehbar. Die Schulden sind dann kein abstraktes Technikproblem mehr, sondern ein bezifferter Kostenfaktor.
Kontinuierlich tilgen statt auf den großen Wurf warten: Der große Refactoring-Sprint, der alles auf einmal löst, kommt in der Praxis selten zustande, weil er schwer zu rechtfertigen ist und das Projekt für Wochen blockiert. Wirkungsvoller ist es, in jedem Sprint einen festen Anteil der Kapazität für technische Pflege zu reservieren. 10 bis 20 Prozent sind eine Größenordnung, die das Feature-Tempo nicht spürbar bremst, aber über Monate und Jahre einen erheblichen Effekt hat.
Fazit
Technische Schulden verschwinden nicht durch Ignorieren. Sie wachsen, und sie kosten: in Entwicklungsgeschwindigkeit, in Qualität, in Motivation des Teams und letztlich in Euro. Der Unterschied zwischen Teams, die technische Schulden im Griff haben, und solchen, die daran scheitern, liegt selten im Budget. Er liegt darin, ob jemand die Schulden sichtbar macht, in der Sprache des Managements beziffert und konsequent in kleinen Portionen tilgt.
Microservices gelten seit Jahren als Goldstandard moderner Softwarearchitektur. In Konferenzvorträgen, Blogposts und Stellenanzeigen wird die Architektur als Zeichen technischer Reife dargestellt. Die Realität ist differenzierter. Viele Teams setzen Microservices ein, ohne dass die Rahmenbedingungen dafür gegeben sind. Heraus kommt nicht bessere Architektur, sondern mehr Komplexität ohne entsprechenden Gegenwert.
Drei Szenarien, die Microservices rechtfertigen
Aus der Erfahrung mit Projekten unterschiedlicher Größenordnung lassen sich drei Szenarien identifizieren, in denen Microservices ihre Stärken tatsächlich ausspielen:
Mehrere Teams arbeiten am selben Produkt: Wenn fünf oder mehr Teams gleichzeitig an einer Anwendung entwickeln, brauchen sie unabhängige Deployment-Zyklen. Ein Team muss seinen Service deployen können, ohne auf das Deployment der anderen warten zu müssen. Microservices ermöglichen das, weil jeder Service seinen eigenen Build- und Release-Prozess hat. Bei zwei bis drei Teams, die eng zusammenarbeiten, lässt sich das auch innerhalb eines Monolithen organisieren. Aber ab einer bestimmten Teamgröße wird die Koordination zum Bottleneck, und separate Services sind die logische Antwort.
Einzelne Komponenten müssen gezielt skaliert werden: Wenn der Bestellprozess hundertmal mehr Last verarbeitet als die Benutzerverwaltung, ist es sinnvoll, beide Komponenten unabhängig skalieren zu können. In einem Monolithen skaliert man immer die gesamte Anwendung, auch die Teile, die gar keine zusätzliche Kapazität brauchen. Microservices erlauben gezielte Skalierung, allerdings nur, wenn die Lastverteilung tatsächlich so ungleichmäßig ist, dass sich der zusätzliche Infrastrukturaufwand lohnt.
Unterschiedliche Technologien sind fachlich begründet: Wenn ein Teil der Anwendung Python für Machine Learning benötigt und ein anderer Java für Transaktionsverarbeitung, können Microservices die technologische Heterogenität sauber kapseln. In der Praxis ist dieser Fall seltener als oft angenommen. Die meisten Anwendungen kommen mit einem Tech-Stack aus.
In den meisten Projekten trifft keiner dieser drei Punkte zu. Die Teamgröße liegt bei 5 bis 15 Entwicklern, die Lastverteilung ist gleichmäßig, und der Tech-Stack ist homogen. Trotzdem entscheiden sich viele Teams für Microservices.
Die tatsächlichen Kosten
Wer Microservices ohne triftigen Grund einführt, bekommt keine bessere Architektur. Die Kosten fallen in vier Bereichen an.
Schnittstellenkomplexität: Jeder Service kommuniziert mit anderen Services über das Netzwerk. Jede Netzwerkkommunikation ist eine potenzielle Fehlerquelle: Verzögerungen, Ausfälle, Wiederholungslogik. In einer einzelnen Anwendung sind interne Aufrufe praktisch fehlerfrei. In einer verteilten Architektur muss für jede Kommunikation eine eigene Fehlerbehandlung existieren. Bei 20 Services mit gegenseitigen Abhängigkeiten multipliziert sich dieser Aufwand erheblich.
Fehlersuche in verteilten Systemen: Wenn ein Request durch fünf Services läuft und irgendwo ein Fehler auftritt, ist die Lokalisierung deutlich aufwändiger als in einem Monolithen. Spezialisierte Überwachungswerkzeuge für jeden einzelnen Service werden notwendig: zentrale Protokollierung, Nachverfolgung von Anfragen über mehrere Systeme hinweg, Monitoring. Diese Werkzeuge müssen eingerichtet, gewartet und vom Team beherrscht werden. In einer einzelnen Anwendung lässt sich ein Fehler in einer einzigen Protokolldatei nachvollziehen.
Deployment- und Infrastrukturaufwand: Statt einer Anwendung deployt man zwanzig. Jede mit eigener CI/CD-Pipeline, eigenem Health-Check, eigener Konfiguration. Container-Orchestrierung, Netzwerk-Management, Versionsverwaltung der einzelnen Dienste: Die Infrastrukturschicht, die für den Betrieb einer Microservice-Architektur nötig ist, erfordert eigenes Know-how und eigene Kapazität. In kleineren Teams bedeutet das, dass ein relevanter Anteil der Arbeitszeit in Infrastruktur fließt statt in fachliche Entwicklung.
Daten-Konsistenz: In einem Monolithen mit einer Datenbank ist eine Transaktion über mehrere Tabellen eine Standardoperation. In einer Microservice-Architektur, in der jeder Service seine eigene Datenbank hat, wird die gleiche Operation zu einer verteilten Transaktion. Die Lösungen dafür existieren, sind aber deutlich aufwändiger umzusetzen und zu testen als eine einfache Datenbanktransaktion in einer einzelnen Anwendung.
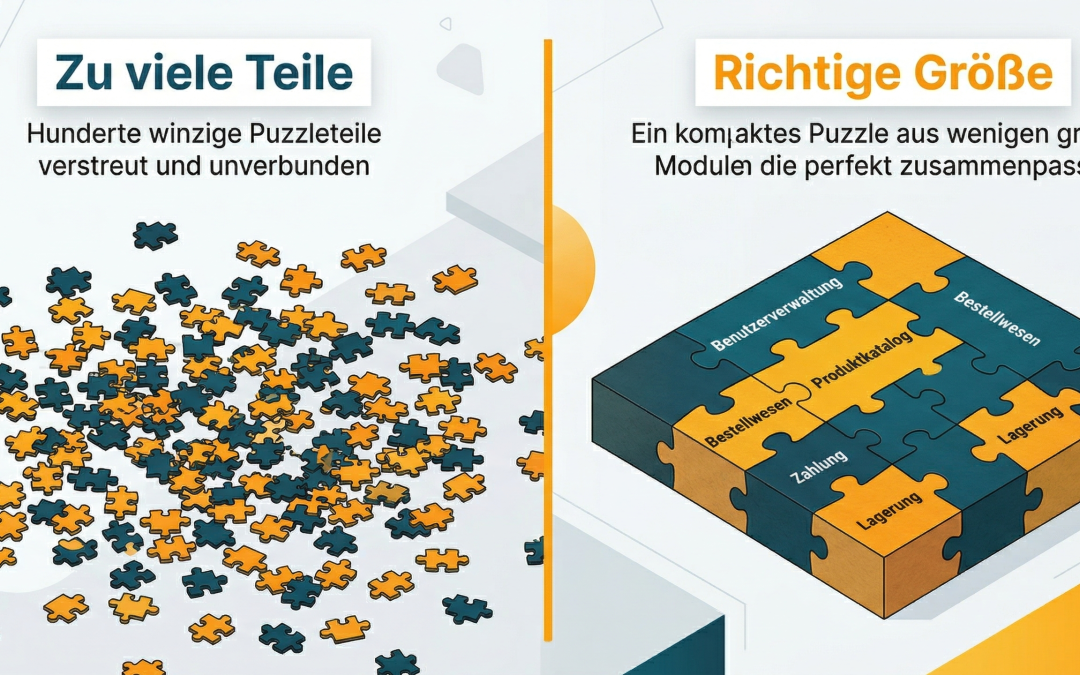
Die Alternative: der modulare Monolith
Ein strukturierter modularer Monolith kombiniert die Vorteile klarer Modulgrenzen mit der Einfachheit eines einzelnen Deployments. Jedes Modul hat definierte Schnittstellen und eigene Verantwortlichkeiten. Aber alles läuft in einem Prozess, mit einer Datenbank, einem Deployment, einem Logging-System.
Der entscheidende Vorteil zeigt sich später. Wenn der Tag kommt, an dem ein Modul tatsächlich als eigenständiger Service laufen muss, weil beispielsweise ein zweites Team daran arbeiten soll oder die Last gezielt skaliert werden muss, ist der Schnitt sauber vorbereitet. Die Modulgrenzen sind definiert, die Schnittstellen klar. Die Extraktion ist ein geplanter Schritt, kein Umbau unter Zeitdruck.
Dieser Ansatz folgt dem Prinzip, Architekturentscheidungen so spät wie möglich zu treffen, nicht so früh wie möglich. Wer zu früh auf Microservices setzt, löst Probleme, die noch gar nicht existieren, und schafft neue, die sofort da sind.
Die richtige Frage stellen
Bevor eine Architekturentscheidung Richtung Microservices fällt, lohnt sich eine ehrliche Bestandsaufnahme: Folgt die Entscheidung einem konkreten technischen Bedarf? Oder folgt sie dem, was Amazon, Netflix und Google machen?
Diese Unternehmen haben Microservices, weil sie tausende Entwickler beschäftigen und Millionen von Nutzern gleichzeitig bedienen. Wenn das eigene Team aus 5 bis 15 Entwicklern besteht und die Anwendung einige hundert gleichzeitige Nutzer hat, ist die Ausgangslage fundamental anders. Architekturentscheidungen sollten sich an den eigenen Rahmenbedingungen orientieren, nicht an denen von Big-Tech-Unternehmen.
Fazit
Microservices sind ein mächtiges Architekturwerkzeug für die Szenarien, in denen sie berechtigt sind: große Teams, ungleichmäßige Lastverteilung, heterogene Technologieanforderungen. Für die Mehrheit der Projekte erzeugen sie mehr Komplexität als Nutzen. Ein modularer Monolith bietet in diesen Fällen die gleiche Flexibilität bei deutlich geringerem Betriebsaufwand. Die beste Architekturentscheidung ist nicht die modernste, sondern die, die zu den tatsächlichen Anforderungen passt.
Sie sehen gerade einen Platzhalterinhalt von Facebook. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von Instagram. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von X. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.